I recently came across a paper by Yilancioglu et al that described a method to predict drug synergies using only lipophilicity. In effect, it claimed to predict synergy based purely on a physicochemical property and independent of target or pathway information. Their results suggest that
combinations of two lipophilic drugs had a greater tendency to show drug synergy
I must admit that I’m skeptical of this claim. While lipophilicity certainly plays a role in a drugs effect (and thereby a drug combinations’ effect), I’m not sure that lipophilicty is a primary driver of a synergistic interaction. Rather, lipophilicity might be a prerequisite; that is, if two molecules cannot enter the cell to access their target(s), they’re unlikely to exhibit synergy!
The paper considered a set of 175 (anti-fungal) drug pairs tested in yeastand evaluated molecular weight, logP, H-bond donor and acceptor counts and also computed a synergicity, that is a measure of how frequently a drug exhibits synergy with other drugs. So the work isn’t really directly capturing synergy (which was measured using the Loewe model). They they compute Spearman correlation between the synergicity and the various physicochemical properties – identifying logP as the one with a statistically significant, though moderate correlation (though one of their examples presents a significant correlation of 0.2 – not a whole lot you could do with that!). They then go on to build a decision tree model that predicts synergicity surprisingly well, though given that the model is based on a synergy netowrk (nodes are drugs, edges are weighted by the synergy between a pair of drugs), it’s not clear how they evaluated the lipophilicity of a drug pair. The terminology was a bit confusing – sometimes using synergicity and sometimes synergy. It’s definitely a surprising result – but is it really meaningful? As I note above, I find it difficult to accept lipophilicty as a proximal driver of synergy. The fact that one of their analyses employs binned logP could raise an issue (see a presentation or this paper on the dangers of binned data).
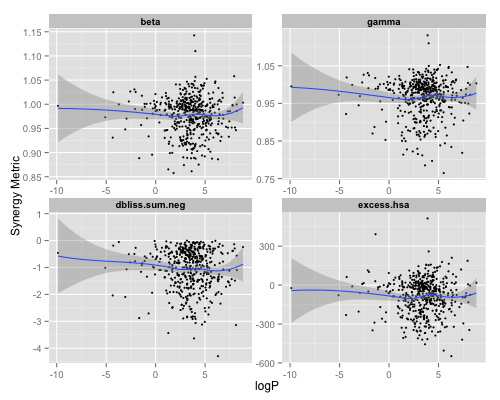 Given that NCATS has developed a high throughput compound combination screening platform, I was interested in seeing if any of this held up on some of our public datasets. I considered a dataset of 466 drugs tested in combination (6×6 matrix) with Ibrutinib. Thus, in contrast to the Yilancioglu et al paper, one member of the combinations is constant. As a result, it makes sense to correlate the logP of the other (i.e., non Ibrutinib) component of the combination to the synergy value of that combination. I evaluated logP of the compounds using ChemAxons cxcalc tool and compared the values to the various synergy metrics we calculate (see here for definitions).
Given that NCATS has developed a high throughput compound combination screening platform, I was interested in seeing if any of this held up on some of our public datasets. I considered a dataset of 466 drugs tested in combination (6×6 matrix) with Ibrutinib. Thus, in contrast to the Yilancioglu et al paper, one member of the combinations is constant. As a result, it makes sense to correlate the logP of the other (i.e., non Ibrutinib) component of the combination to the synergy value of that combination. I evaluated logP of the compounds using ChemAxons cxcalc tool and compared the values to the various synergy metrics we calculate (see here for definitions). 
The figure above pretty much shows no correlation for any of the synergy metrics (and Spearmans ρ was ≅ 0 with p > 0.05). I also repeated the calculation of a set of 1912 combinations (i.e., 1912 compounds combined with Ibrutinib) and got essentially the same result. Granted that this was on a single lymphoma cell line (TMD8) which is significantly different from the environment considered by the authors and that our synergy metrics are different from those described in the paper. So, it might just be a feature of anti-fungal drugs?
But interestingly, when we considered binned logP values and look at the median value of a synergy metric in each logP bin, we do see a trend – at least for two out of four metrics. But given the scatter plots, where the variability is not hidden, is this really meaningful?
So overall, the paper presents some surprising observations but is a little unsatisfying from an explanatory point of view. And the conclusions don’t seem to translate to other datasets.