I recently came across http://www.casesdatabase.com/ from BMC, a collection of more than 29,000 peer-reviewed case studies collected from a variety of journals. I’ve been increasingly interested in the possibilities of mining clinical data (inspired by impressive work from Atul Butte, Nigam Shah and others), so this seemed like a great resource to explore
The folks at BMC have provided a REST API, which is still in development – as a result, there’s no public documentation and it still has a few rough edges. However, thanks to help from Demitrakis Kavallierou, I was able to interact with the API and extract summary search information as well as 28,998 case studies as of Sept 23, 2013. I’ve made the code to extract case studies available as proc.py. Running this, gives you two sets of data.
- A JSON file for each year between 2000 and 2014, containing the summary results for all cases in that year which includes a summary view of the case, plus facets for a variety of fields (age, condition, pathogen, medication, intervention etc.)
- A pickle file containing the case reports, as a list of maps. The case report contains the full abstract, case report identifier and publication meta-data.
A key feature of the case report entries is that BMC has performed some form of entity recognition so that it provides a list of keywords identified by different types: ‘Condition’, ‘Symptom’, ‘Medication’ etc. Each case may have multiple occurences for each type of keyword and importantly, each keyword is associated with the text fragment it is extracted from. As an example consider case 10.1136/bcr.02.2009.1548. The entry extracts two conditions
1 2 3 | {u'sentence': u'She was treated by her family physician for presumptive interscapular myositis with anti-inflammatory drugs, cold packs and rest.', u'text': u'Myositis', u'type': u'Condition'} |
and
1 2 3 | {u'sentence': u'The patient denied any constitutional symptoms and had no cough.', u'text': u'Cough', u'type': u'Condition'} |
I’m no expert in biomedical entity recognition, but the fact that BMC has performed it, saves me from having to become one, allowing me to dig into the data. But there are the usual caveats associated with text mining – spelling variants, term variants (insulin and insulin therapy are probably equivalent) and so on.

Count of cases deposited per year
However, before digging into the cases themselves, we can use the summary data, and especially the facet information (which is, by definition, standardized) to get some quick summaries from the database. For example we see the a steady increase of case studies deposited in the literature over the last decade or so.
Interestingly, the number of unique conditions, medications or pathogens reported for these case studies is more or less constant, though there seems to be a downward trend for conditions. The second graph highlights this trend, by plotting the number of unique facet terms (for three types of facets) per year, normalized by the number of cases deposited that year.
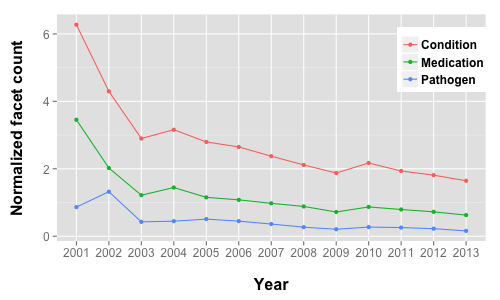
Normalized count of unique facet terms by year
This is a rough count, since I didn’t do any clean up of the text – so that misspellings of the same term (say, acetaminophen and acetaminaphen will be counted as two separate medication facets) may occur.
Another interesting task would be to enrich the dataset with additional annotations – ICD9/ICD10 for conditions, ATC for drugs – which would allow a higher level categorization and linking of case studies. In addition, one could use the CSLS service to convert medication names to chemical structures and employ structural similarity to group case studies.
The database also records some geographical information for each case. Specifically, it lists the countries that the authors are from. While interesting to an extent, it would have been nice if the country of occurrence or country of treatment were specifically extracted from the text. Currently, one might infer that the treatment occurred in the same country as the author is from, but this is likely only true when all authors are from the same country. Certainly, multinational collaborations will hide the true number of cases occurring in a given country (especially so for tropical diseases).
But we can take a look at how the number of cases reported for specific conditions, varies with geography and time. The figure below shows the cases whose conditions included the term tuberculosis
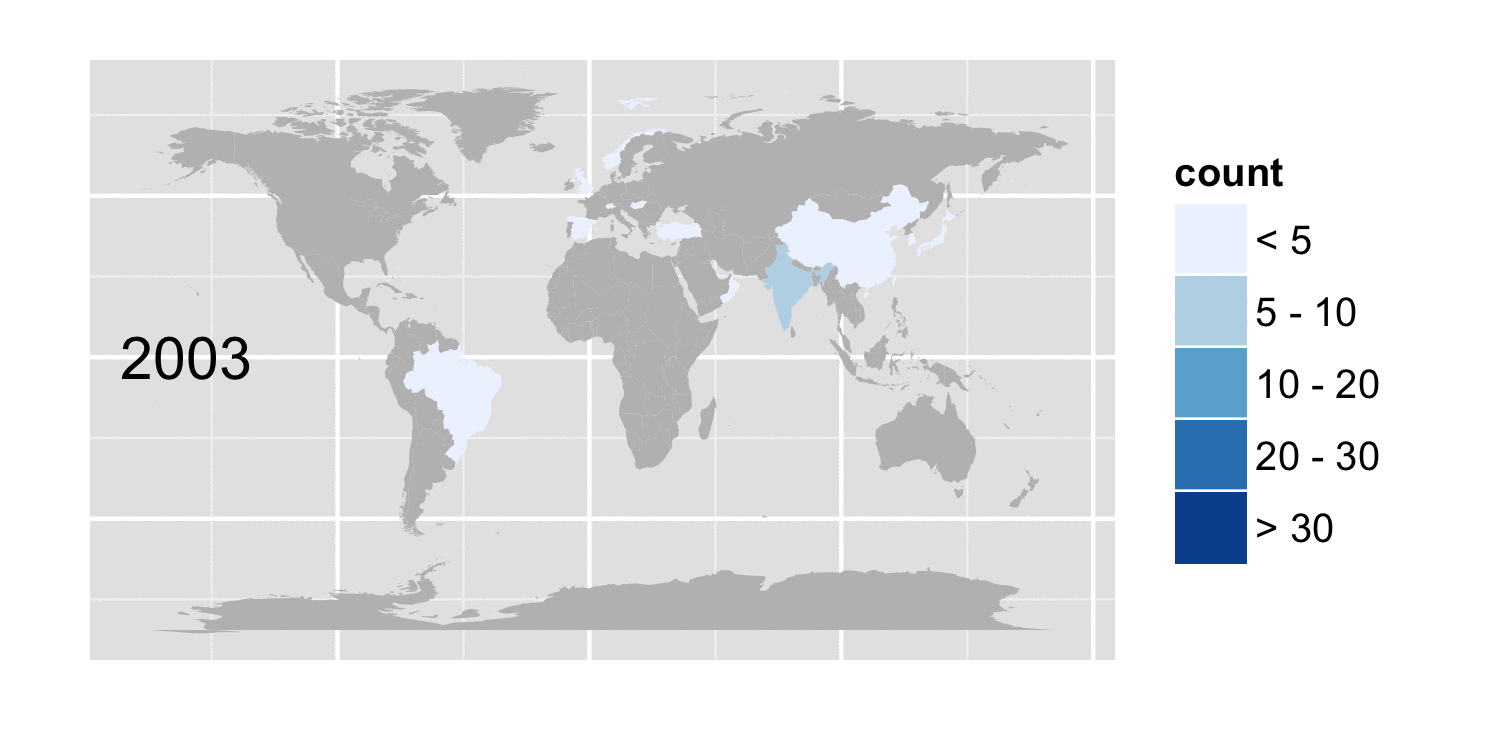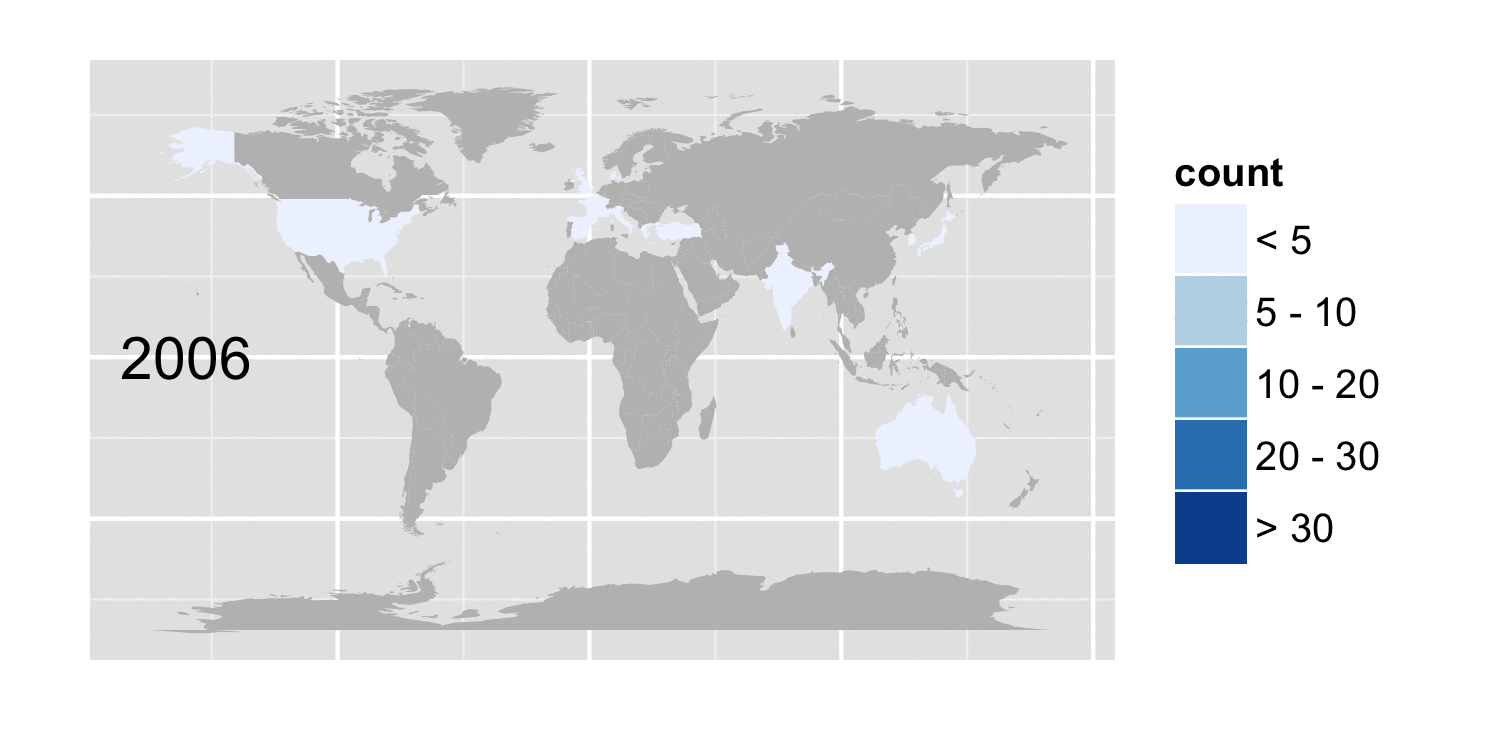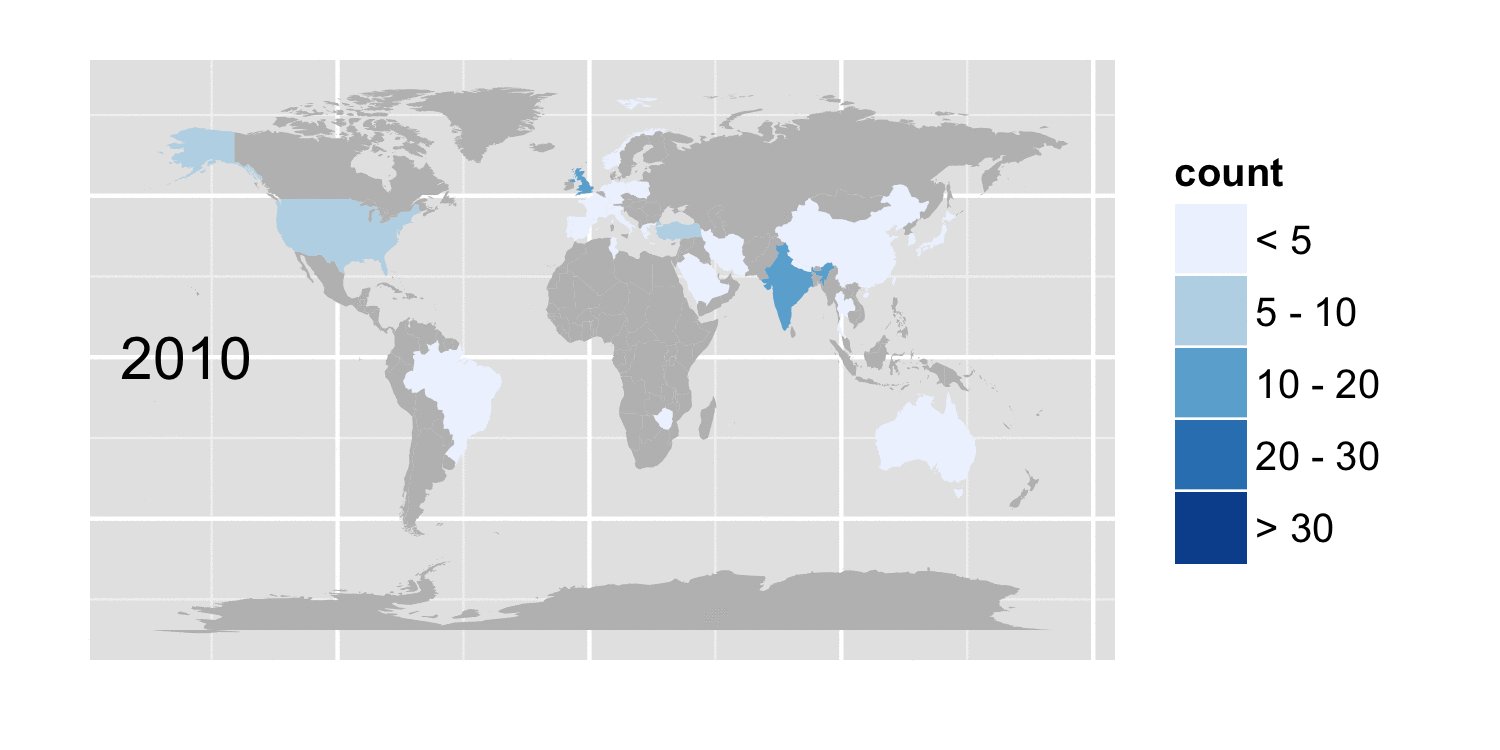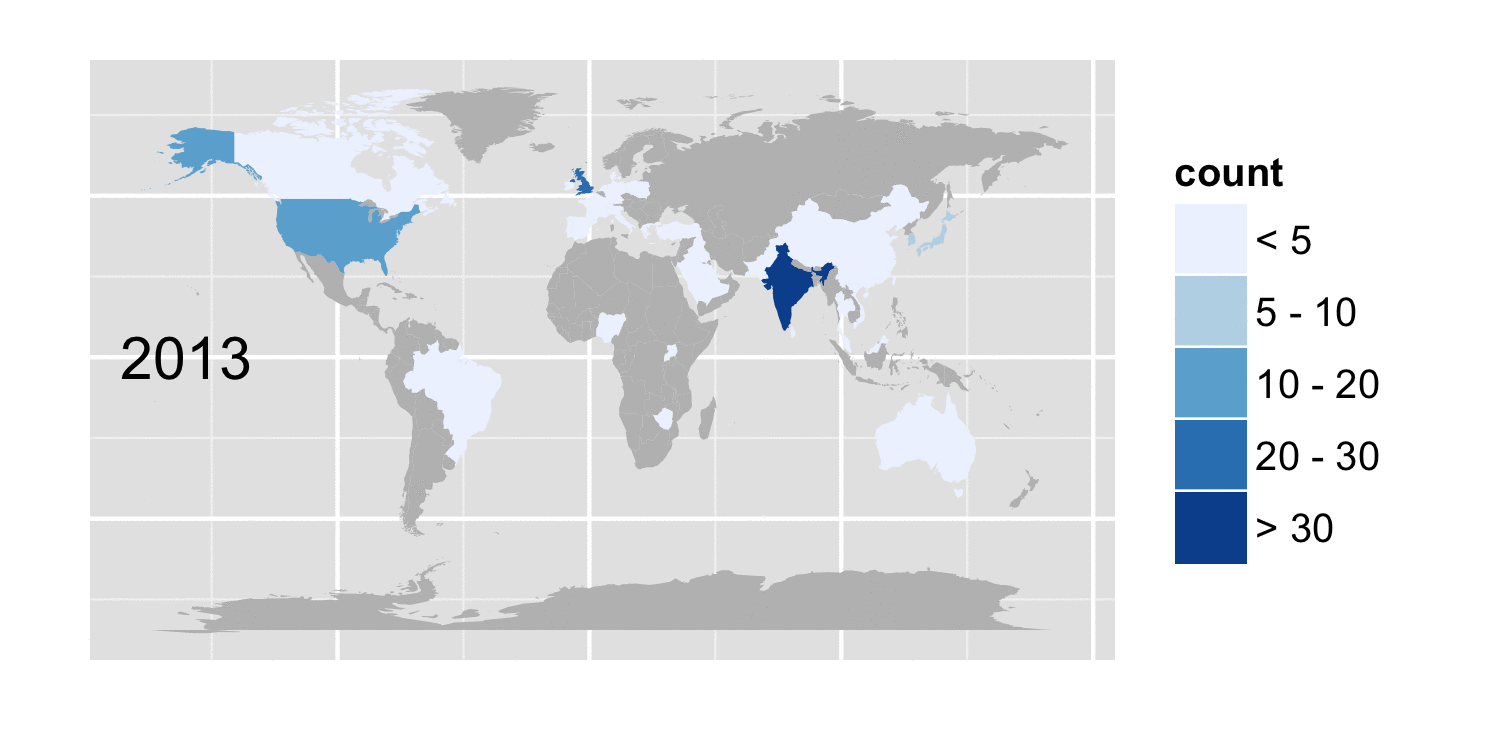
Tuberculosis cases by country and year
The code to extract the data from the pickle file is in condition_country.py. Assuming you have cases.pickle in your current path, usage is
1 | $ python condition_country.py condition_name |
and will output the data into a CSV file, which you can the process using your favorite tools.
In following blog posts, I’ll start looking at the actual case studies themselves. Interesting things to look at include exploring the propensity of co-morbidities, analysing the co-occurrence of conditions and medications or conditions and pathogens, to see whether the set of treatments associated with a given condition (or pathogen) has changed over time. Both these naturally lead to looking at the data with eye towards repurposing events.
[…] previous post described a first look at the data available in casesdatabase.com, primarily looking at […]